
پیش پردازش داده، جزئی از آماده سازی داده ها است که هر نوع پردازشی را که بر روی داده های خام انجام می شود توصیف می کند تا آن را برای پردازش داده دیگر آماده کند. این رویکرد به طور سنتی یک مرحله مقدماتی مهم برای فرآیند داده کاوی بوده است. اخیراً، تکنیکهای پیش پردازش داده ها برای آموزش مدل های یادگیری ماشین و مدل های هوش مصنوعی و برای اجرای آنها استفاده میشوند.
پیش پردازش داده ها، دادهها را به قالبی تبدیل میکند که در داده کاوی، یادگیری ماشین و سایر کارهای علم داده پردازش آسانتر و مؤثرتری اتفاق بیفتد. این تکنیکها معمولاً در مراحل اولیه یادگیری ماشین و توسعه هوش مصنوعی برای اطمینان از نتایج دقیق استفاده میشوند.
ابزارهای پیش پردازش داده
ابزارها و روشهای مختلفی برای پیش پردازش دادهها استفاده می شود، از جمله:
- نمونه گیری : یک زیرمجموعه نماینده را از جمعیت بزرگی از دادهها انتخاب میکند.
- تبدیل : دادههای خام را برای تولید یک ورودی واحد دستکاری میکند.
- حذف نویز : نویز را از دادهها حذف میکند.
- انتساب : داده های آماری مرتبط را برای مقادیر از دست رفته ترکیب میکند.
- استخراج ویژگی : یک زیرمجموعه ویژگی مرتبط را که در یک زمینه خاص مهم است، بیرون میکشد.
پیش پردازش داده ها چرا مهم است؟
دادههای دنیای واقعی کثیف هستند و اغلب توسط انسانها، فرآیندهای کسب و کار و برنامههای کاربردی مختلف ایجاد، پردازش و ذخیره میشوند. در نتیجه، یک مجموعه داده ممکن است فیلدهای جداگانه نداشته باشد، حاوی خطاهای ورودی دستی باشد، یا داده های تکراری یا نامهای متفاوتی برای توصیف یک رکورد داشته باشد. انسانها اغلب میتوانند این مشکلات را در دادههایی که در مسیر کسب و کار استفاده میکنند شناسایی و اصلاح کنند، اما دادههایی که برای آموزش یادگیری ماشین یا الگوریتمهای یادگیری عمیق استفاده میشوند باید به طور خودکار پیش پردازش شوند.
الگوریتمهای یادگیری ماشین و یادگیری عمیق زمانی بهترین عملکرد را دارند که دادهها در قالبی ارائه شوند که جنبههای مرتبط مورد نیاز برای حل یک مشکل را برجسته کنند. روشهای مهندسی ویژگیها که شامل تبدیل دادهها، کاهش دادهها، انتخاب ویژگی و مقیاسبندی ویژگی است، به بازسازی دادههای خام به شکلی مناسب برای انواع خاصی از الگوریتمها کمک میکنند. این امر میتواند به طور قابل توجهی قدرت پردازش و زمان مورد نیاز برای آموزش یک الگوریتم یادگیری ماشینی یا هوش مصنوعی جدید را کاهش دهد.
مراحل کلیدی در پیش پردازش داده ها چیست؟
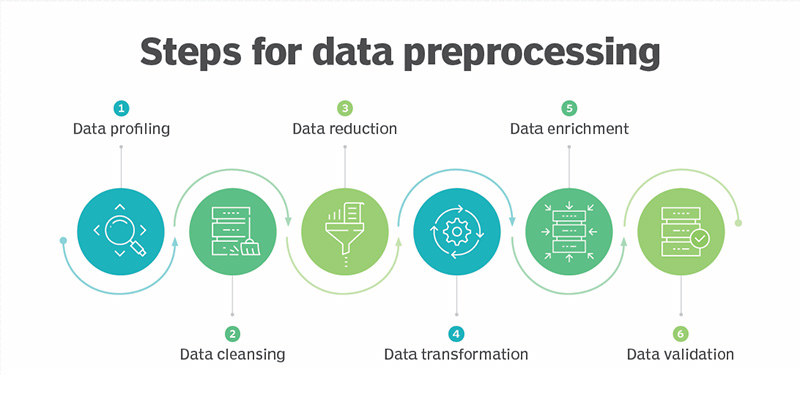
مراحل مورد استفاده در پیش پردازش دادهها شامل موارد زیر است:
- پروفایل داده: پروفایل دادهها فرآیند بررسی، تجزیه و تحلیل و بررسی دادهها برای جمع آوری آمار در مورد کیفیت آن است. این مرحله با بررسی دادههای موجود و ویژگیهای آن شروع میشود. متخصصان داده مجموعههای دادهای را شناسایی میکنند که مربوط به مسئله مورد نظر هستند، ویژگیهای مهم آن را فهرستبندی میکنند و فرضیهای از ویژگیهایی را تشکیل میدهند که ممکن است برای تحلیل پیشنهادی یا کار یادگیری ماشین مرتبط باشند. آنها همچنین منابع داده را به مفاهیم کسب و کار مرتبط مرتبط میکنند و در نظر میگیرند که کدام کتابخانههای پیش پردازش پایتون میتوانند مورد استفاده قرار گیرند.
- پاکسازی دادهها: هدف در اینجا یافتن سادهترین راه برای اصلاح مشکلات کیفیت است، مانند حذف دادههای اضافی، پر کردن دادههای از دست رفته یا اطمینان از مناسب بودن دادههای خام برای مهندسی ویژگیها.
- کاهش دادهها: مجموعه دادههای خام اغلب شامل دادههای اضافی میشوند که از توصیف پدیدهها به روشهای مختلف یا دادههایی که به یک کار خاص ML، AI یا تجزیه و تحلیل مرتبط نیستند، ناشی میشوند. روش کاهش دادهها از تکنیکهایی مانند تجزیه و تحلیل مؤلفههای اصلی برای تبدیل دادههای خام به شکل سادهتر مناسب برای موارد استفاده خاص استفاده میکند.
- تبدیل دادهها: در اینجا، متخصصان داده به این فکر میکنند که چگونه جنبههای مختلف دادهها باید سازماندهی شوند تا بیشترین معنا را برای هدف داشته باشند. این مرحله میتواند شامل مواردی مانند ساختار دادن به دادههای بدون ساختار و تمرکز روی آنها باشد.
- غنی سازی دادهها: در این مرحله، متخصصان داده، کتابخانههای مهندسی ویژگیهای مختلف را روی دادهها اعمال میکنند تا تبدیلهای مورد نظر را اعمال کنند. نتیجه باید مجموعه دادهای باشد که برای دستیابی به تعادل بهینه بین زمان آموزش برای یک مدل جدید و محاسبات مورد نیاز سازماندهی شده است.
- اعتبار سنجی دادهها: در این مرحله دادهها به دو مجموعه تقسیم میشوند. اولین مجموعه برای آموزش یک مدل یادگیری ماشین یا یادگیری عمیق استفاده میشود. مجموعه دوم دادههای آزمایشی است که برای سنجش دقت و استحکام مدل به دست آمده استفاده میشود. این مرحله دوم به شناسایی هرگونه مشکل در فرضیه استفاده شده در تمیز کردن و مهندسی ویژگی دادهها کمک میکند. اگر متخصصان داده از نتایج راضی باشند، می توانند وظیفه پیش پردازش را به یک مهندس داده سوق دهند که چگونگی مقیاس بندی آن را برای تولید بیابد. در غیر این صورت، متخصصان داده میتوانند به عقب برگردند و تغییراتی در نحوه اجرای مراحل پاکسازی دادهها و مهندسی ویژگیها ایجاد کنند.
پیشنهاد بهفالب : مدلسازی فرآیند چیست؟
تکنیک های پیش پردازش داده ها
دو دسته اصلی پیش پردازش وجود دارد: تمیز کردن دادهها و مهندسی ویژگی دادهها. هر کدام شامل تکنیک های متنوعی است که در زیر توضیح داده شده است.
تمیز کردن داده ها

تکنیکهای پاکسازی دادههای نامرتب شامل موارد زیر است:
داده های از دست رفته را شناسایی و مرتب کنید: دلایل مختلفی وجود دارد که یک مجموعه داده ممکن است فیلدهای جداگانه داده را از دست بدهد. متخصصان داده باید تصمیم بگیرند که آیا بهتر است رکوردهای دارای فیلدهای گمشده را کنار بگذارند، آنها را نادیده بگیرند یا آنها را با مقدار احتمالی پر کنند. به عنوان مثال، در یک برنامه IoT که دما را ثبت میکند، اضافه کردن یک میانگین دمای از دست رفته بین رکورد قبلی و بعدی ممکن است راه حل مطمئنی باشد.
دادههای نویزی را کاهش دهید: دادههای دنیای واقعی اغلب پر از نویز هستند که میتواند مدل تحلیلی یا هوش مصنوعی را مخدوش کند. به عنوان مثال، یک سنسور دما که به طور مداوم دمای 75 درجه فارنهایت را گزارش میکند ممکن است به اشتباه دما را 250 درجه گزارش کند. انواع روشهای آماری را میتوان برای کاهش نویز استفاده کرد، از جمله binning، رگرسیون و خوشه بندی.
موارد تکراری را شناسایی و حذف کنید: هنگامی که دو رکورد تکرار می شوند، یک الگوریتم باید تعیین کند که آیا یک اندازه گیری دو بار ثبت شده است یا اینکه رکوردها نشان دهنده رویدادهای مختلف هستند. در برخی موارد، ممکن است تفاوت های جزئی در یک رکورد وجود داشته باشد زیرا یک فیلد به اشتباه ثبت شده است. در موارد دیگر، سوابقی که به نظر تکراری هستند ممکن است واقعاً متفاوت باشند، مانند پدر و پسری با نام مشابه که در یک خانه زندگی میکنند اما باید به عنوان افراد جداگانه نشان داده شوند. تکنیکهای شناسایی و حذف یا پیوستن موارد تکراری میتواند به رفع خودکار این نوع مشکلات کمک کند.
مهندسی ویژگی
مهندسی ویژگی، همانطور که اشاره شد، شامل تکنیکهایی است که توسط متخصصان داده برای سازماندهی دادهها به روشهایی که آموزش مدلهای داده و استنتاج بر اساس آنها را کارآمدتر میکند، استفاده میکند. این تکنیک ها شامل موارد زیر است:
مقیاس بندی یا نرمال سازی ویژگی: اغلب، چندین متغیر در مقیاسهای مختلف تغییر میکنند، یا یکی به صورت خطی تغییر میکند در حالی که متغیر دیگر به صورت تصاعدی تغییر میکند. به عنوان مثال، حقوق ممکن است با هزاران دلار اندازه گیری شود، در حالی که سن به صورت دو رقمی نشان داده میشود. مقیاسبندی به تغییر شکل دادهها کمک میکند تا الگوریتمها بتوانند رابطه معنادار بین متغیرها را از هم جدا کنند.
کاهش دادهها: متخصصان داده اغلب نیاز به ترکیب انواع منابع داده برای ایجاد یک مدل هوش مصنوعی یا تحلیلی جدید دارند. برخی از متغیرها ممکن است با یک نتیجه مشخص همبستگی نداشته باشند و با خیال راحت کنار گذاشته شوند. سایر متغیرها ممکن است مرتبط باشند، اما فقط از نظر رابطه – مانند نسبت بدهی به اعتبار در مورد مدلی که احتمال بازپرداخت وام را پیشبینی میکند. تکنیکهایی مانند تحلیل مؤلفههای اصلی نقش کلیدی در کاهش تعداد ابعاد در مجموعه دادههای آموزشی به نمایش کارآمدتر دارند.
جمع بندی
در آخر باید اشاره کنیم که پیشپردازش دادهها یکی از مراحل کلیدی و حیاتی در فرآیندکاوی محسوب میشود. در این مرحله، لاگها و دادههای رویدادی خام که از سیستمهای اطلاعاتی جمعآوری شدهاند، پس از انجام عملیات پاکسازی و استانداردسازی، آمادهی تجزیه و تحلیل توسط الگوریتمها و روشهای کشف فرآیند میگردند. پس از آمادهسازی دادهها، میتوان فرایندکاوی را بر روی آنها اعمال نموده و الگوها و بینشهای ارزشمندی را در رابطه با عملکرد و بهرهوری فرایندهای کسب و کار استخراج کرد.


