نگاره رویداد پایه ای برای مصورسازی مدل های فرآیند و در نتیجه فرآیندکاوی هستند. اما نگاره رویداد چگونه به نظر می رسد و مراحل انجام پروژه فرآیندکاوی چیست؟ پاسخ این سوالات را می توانید در مقاله فرایندکاوی چیست بخوانید. این بار می خواهیم الگوریتم های فرآیندکاوی مورد نیاز برای تبدیل یک رویداد نگاره به یک مدل فرآیند را معرفی کنیم.
الگوریتم های فرایندکاوی
مولفه اصلی در فرآیندکاوی الگوریتمهای کاوش است. الگوریتمها نحوه ایجاد مدلهای فرآیند را تعیین میکنند. طیف گستردهای از الگوریتمهای کاوش وجود دارد. سه دسته زیر با جزئیات بیشتری مورد بحث قرار خواهیم گرفت.
- الگوریتمهای کاوش قطعی
- الگوریتمهای کاوش اکتشافی
- الگوریتمهای کاوش ژنتیک
قطعی بودن به این معنی است که یک الگوریتم فقط نتایج تعریف شده و قابل تکرار تولید میکند و همیشه نتیجه مشابهی را برای ورودی مشابه ارائه میدهد. نماینده این دسته، الگوریتم آلفا است. این الگوریتم از اولین الگوریتمهایی بود که قادر به مقابله و کنترل همزمانی بود. این الگوریتم یک ورودی از نگاره رویداد میگیرد و ترتیب رویدادها و فعالیتهای موجود در نگاره را مشخص میکند. روش کاوش اکتشافی نیز از این الگوریتمهای قطعی استفاده میکند. اما آنها فرکانسهای وقایع و ردیابیها آنها را برای بازسازی یک مدل فرآیند را در بر میگیرند. یک مشکل رایج در فرآیندکاوی این واقعیت است که فرایندهای واقعی بسیار پیچیده هستند و کشف آنها منجر به مدلهای پیچیده میشود. با نادیده گرفتن مسیرهای نادر در مدلها می توان این پیچیدگیها را کاهش داد.
الگوریتمهای کاوش ژنتیک از یک رویکرد تکاملی استفاده میکنند که روند تکامل طبیعی را تقلید میکند. الگوریتمهای کاوش ژنتیک چهار مرحله اصلی دارد: شروع اولیه، انتخاب، تولید دوباره و خاتمه. ایده پشت این الگوریتمها ایجاد یک جمعیت تصادفی از مدلهای فرآیندی و یافتن یک راه حل رضایت بخش با انتخاب تکراری افراد و تولید دوباره آنها با استفاده از جهش در نسلهای مختلف است. جمعیت اولیه مدلهای فرآیندی به طور تصادفی تولید میشود و ممکن است اشتراکات کمی با نگاره رویداد داشته باشد. اما به دلیل تعداد زیاد مدلها در جمعیت و همچنین انتخاب و تولید دوباره، در نسلهای جدید مدلهای مناسبتری ایجاد میشوند.
نتایج کاوش بسته به الگوریتم مورد استفاده متفاوت است. ما برای نشان دادن مدلهای ایجاد شده توسط الگوریتمهای مختلف کاوش و برای ارائه تصویری از نحوه کار کاوش، از نگاره رویداد نمایش داده شده در جدول زیر استفاده خواهیم کرد.
|
شناسهی پرونده |
شناسهی رویداد | برچسب زمانی | فعالیت |
منبع کاری |
|
1 |
1000 | 01/02/1400 | سفارش کالا | گودرزی |
|
1001 |
04/02/1400 |
دریافت کالا |
نوروزیان |
|
|
1002 |
07/02/1400 | دریافت فاکتور |
نظرزاده |
|
|
1003 |
10/02/1400 |
پرداخت فاکتور |
کرمانی |
|
| 2 | 1004 | 13/02/1400 | سفارش کالا |
گودرزی |
|
1005 |
16/02/1400 | دریافت کالا | نوروزیان | |
| 1006 | 20/02/1400 | دریافت فاکتور |
نظرزاده |
|
| 1007 | 24/02/1400 | پرداخت فاکتور |
کرمانی |
|
|
3 |
1008 | 28/02/1400 | سفارش کالا | گودرزی |
|
1009 |
31/02/1400 | دریافت کالا |
نوروزیان |
|
| 1010 | 03/03/1400 | دریافت فاکتور |
نظرزاده |
|
| 1011 | 10/03/1400 | پرداخت فاکتور |
کرمانی |
|
|
4 |
1016 | 15/03/1400 | سفارش کالا | گودرزی |
|
1017 |
18/03/1400 |
دریافت کالا | نوروزیان | |
|
1018 |
25/03/1400 | دریافت فاکتور |
نظرزاده |
|
|
1019 |
31/03/1400 | پرداخت فاکتور |
کرمانی |
جدول نگاره رویداد
شکل 1 یک مدل فرآیند کاوش شده را نشان میدهد که با استفاده از الگوریتم آلفا در نگاره رویداد نمونه بازسازی شده است. این فرایند برای مقایسه بهتر به مدل BPMN ترجمه شده است. در پرونده 3، فاکتور قبل از کالا دریافت میشود. با توجه به اینکه هر دو احتمال در نگاره رویداد وجود دارد (کالاهای دریافت شده قبل از فاکتور در پروندههای 1، 2، 5 و فاکتور دریافت شده قبل از کالاهای سفارش داده شده در پرونده 3)، الگوریتم کاوش فرض میکند که این فعالیتها به طور همزمان قابل انجام است.
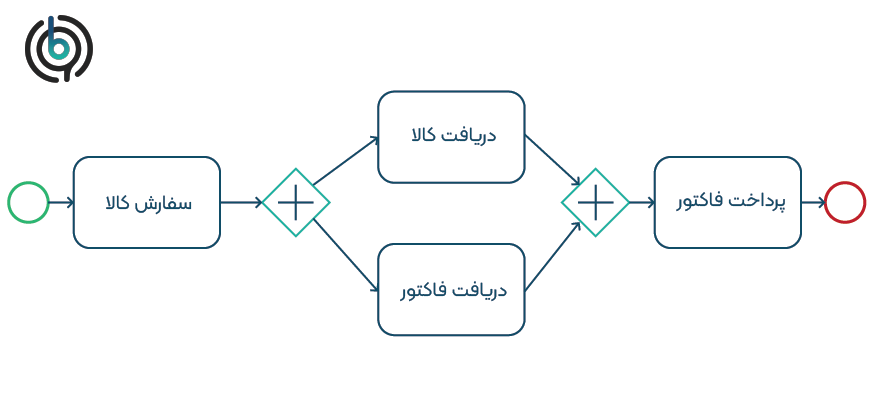
شکل 1: مدل فرآیند کاوش شده با استفاده از الگوریتم آلفا
هنگامی که کمی به مدل 1 نگاه میکنیم، میتوانیم واقعیت مهم دیگری را نیز مشاهده کنیم. پرونده 4 در واقع در مدل فرآیند منعکس نشده است. این مدل قادر به پیادهسازی پرونده 4 نیست. دو توالی اجرای احتمالی ABCD و ACBD برای این مدل امکان پذیر است. اما توالی ACD امکان پذیر نیست. درگاه انتهایی پس از فعالیت “سفارش کالا” مستلزم اجرای هر دو شاخه قبل خود است. بنابراین، بدون اجرای فعالیت B امکان توالی اجرا نیست. این مدل از تناسب ضعیفی برخوردار است زیرا قادر به نشان دادن کلیه مسیرهای احتمالی نگاره رویداد نیست. مدل نشان داده شده در شکل 2 قادر به پخش مجدد تمام مسیرهای احتمالی است. با توجه به درگاههای اختصاصی، هر سه مسیر ABCD ،ACBD و ACD امکان پذیر است. اما اکنون مسئله این است که توالیهای اجرای بسیار بیشتری تا آنچه در نگاره رویداد منعکس شده است وجود دارد. در حقیقت مدل فرآیند مجموعهای بی نهایت از توالیها را امکان پذیر میکند. اکنون حلقهها ممکن است یا از B به C شروع شوند یا از C به B منجر به توالیهای احتمالی با تکرارهای بینهایت B و C یا C و B شوند. برای مثال توالی ABCBCD ممکن است، اگرچه به عنوان یک ردیف در نگاره رویداد وجود ندارد.
اگر یک مدل فرآیند بیش از حد عمومی باشد، گفته می شود که “کم برازش” است و از دقت کافی برخوردار نیست. یک چالش عمده در فرآیندکاوی، یافتن راه حل مناسب بین تناسب، دقت، سادگی و تعمیم پذیری است:
تناسب: تناسب میزان اینکه مدل کشف شده با چه دقتی میتواند پروندههای ثبت شده در نگاره رویداد را دوباره تولید کند، محاسبه کند.
دقت: دقت میزان رفتار مجاز توسط مدل که در نگاره رویداد مشاهده نمیشود را محاسبه میکند.
سادگی: پیچیدگی یک مدل فرآیند توسط بعد سادگی جذب میشود.
تعمیم پذیری: تعمیم ارزیابی میکند که مدل حاصل تا چه اندازه قادر به بازتولید رفتارهای آینده فرآیند میتواند باشد.
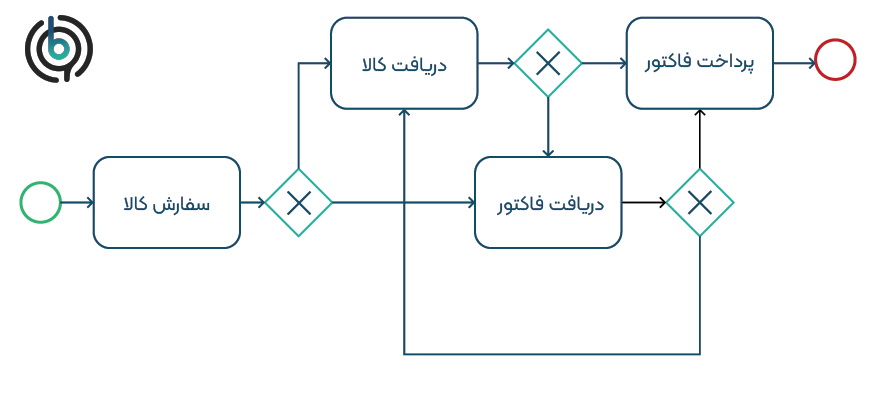
شکل 2: مدل فرآیند کم برازش
الگوریتمهای مختلف کاوش پیشرفته وجود دارد که میتوانند برای اهداف مختلف مورد استفاده قرار گیرند. شکل 3 مدل کاوش شده را با استفاده از الگوریتم ابتکاری کاوشگر Fuzzy نشان میدهد. این مدل از علامتگذاری BPMN پیروی نمیکند بلکه در عوض از نمایش نمودار وابستگی استفاده میکند. این شکل شامل هیچ عملگر درگاهی نیست اما وابستگی بین فعالیتهای مختلف را نشان میدهد. نمودار وابستگی به عنوان مثال نشان میدهد که A سه بار توسط B و دو بار توسط C دنبال میشود.
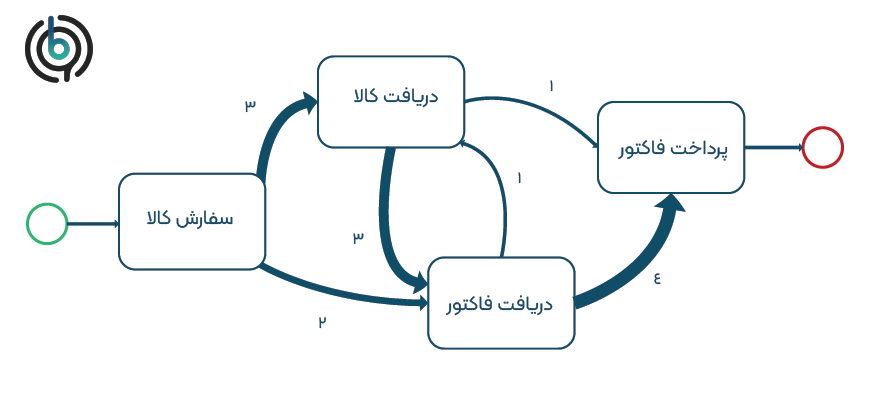
تشخیص اینکه کدام یک از نیازها برای دستیابی به اهداف مورد نظر برای هر پروژه کاوش فرآیند در نظر گرفته میشود، مهم است. مناسب بودن یک الگوریتم باید بسته به منطقه کاربرد آن ارزیابی شود.
در این مقاله به کلیت الگوریتمهای فرایندکاوی ونحوهی کار آنها جدا از ریاضیات و محاسبه پیچیدهی آن پرداختیم. فرایندکاوی الگوریتمهای بیشتری دارد ولی ما در اینجا مهمترین و پرکاربردترین آنها را معرفی و توضیح دادیم. در مقالههای بعدی نحوهی کار فرایندکاوی را به طور کامل توضیح میدهیم.