یادگیری ماشین یا Machine Learning را می توان به صورت خودکارسازی و بهبود فرآیند یادگیری کامپیوترها بر اساس تجربیات آن ها بدون برنامه ریزی، یعنی بدون کمک انسانی تعریف کرد. این فرآیند با تغذیه داده های با کیفیت خوب و سپس آموزش ماشین ها (کامپیوترها) با ساخت مدل های یادگیری ماشین با استفاده از داده ها و الگوریتمهای مختلف آغاز می شود. انتخاب الگوریتم ها بستگی به نوع داده های ما و چه نوع وظیفه ای دارد که می خواهیم خودکار کنیم.
پیشنهاد بهفالب : اتوماسیون صنعتی چیست؟
یادگیری ماشین چیست؟
یادگیری ماشین شاخهای از هوش مصنوعی است که الگوریتمهایی را با یادگیری الگوهای پنهان مجموعه دادههایی که از آن برای پیشبینی دادههای نوع مشابه جدید استفاده میکنند، توسعه میدهد، بدون اینکه به طور صریح برای این کار برنامهریزی شود.
یادگیری ماشین سنتی دادهها را با ابزارهای آماری ترکیب میکند تا خروجیهایی را پیشبینی کند که میتوان از آن برای ایجاد بینشهای عملی استفاده کرد.
یادگیری ماشینی در بسیاری از برنامههای کاربردی مختلف، از تشخیص تصویر و گفتار گرفته تا پردازش زبان طبیعی، سیستمهای توصیه، تشخیص تقلب، بهینهسازی پورتفولیو، وظایف خودکار و غیره استفاده میشود. مدلهای یادگیری ماشین همچنین برای نیرو دادن به وسایل نقلیه خودران، پهپادها و روباتها استفاده میشوند و آنها را باهوشتر و سازگارتر با محیطهای متغیر میسازد.
یک کار معمول یادگیری ماشین ارائهی توصیه است. سیستمهای توصیه کننده یک کاربرد رایج از یادگیری ماشین هستند و از دادههای تاریخی برای ارائه توصیههای شخصی به کاربران استفاده میکنند. در Netflix، این سیستم از فیلتر مبتنی بر محتوا استفاده میکند تا فیلمها و برنامههای تلویزیونی را به کاربران بر اساس سابقه مشاهده، رتبهبندی و سایر عوامل مانند ژانر توصیه کند.
این پیشرفت با این ایده حاصل میشود که یک ماشین میتواند به طور منحصر به فرد از دادهها یاد بگیرد تا نتایج دقیق تولید کند. یادگیری ماشین ارتباط نزدیکی با داده کاوی و علم داده دارد. ماشین دادهها را به عنوان ورودی دریافت میکند و از یک الگوریتم برای فرمول بندی پاسخها استفاده میکند.
پیشنهاد بهفالب : داده کاوی در مقابل فرایندکاوی
تفاوت بین یادگیری ماشین و برنامه نویسی سنتی
تفاوت بین یادگیری ماشین و برنامه نویسی سنتی به شرح زیر است:
| یادگیری ماشین | برنامه نویسی سنتی | هوش مصنوعی |
| یادگیری ماشینی زیرمجموعهای از هوش مصنوعی (AI) است که بر یادگیری از دادهها تمرکز میکند تا الگوریتمی ایجاد کند که بتوان از آن برای پیشبینی استفاده کرد. | در برنامه نویسی سنتی، کدهای مبتنی بر قانون توسط برنامه نویسان، بسته به وضعیت نوشته میشود. | هوش مصنوعی شامل ساختن ماشین با بیشترین توان است، به طوری که بتواند وظایفی که معمولاً به هوش انسانی نیاز دارد را انجام دهد. |
| یادگیری ماشین از یک رویکرد داده محور استفاده میکند و معمولاً بر روی دادههای تاریخی آموزش داده میشود. سپس برای پیش بینی دادههای جدید مورد استفاده قرار میگیرد. | برنامه نویسی سنتی معمولاً مبتنی بر قانون و قطعی است. ویژگیهای خودآموزی مانند یادگیری ماشینی و هوش مصنوعی ندارد. | هوش مصنوعی میتواند تکنیکهای مختلفی از جمله یادگیری ماشین و یادگیری عمیق و همچنین برنامه نویسی مبتنی بر قوانین سنتی را شامل شود. |
| یادگیری ماشین میتواند الگوها و بینشهایی را در مجموعه دادههای بزرگ پیدا کند که کشف آنها ممکن است برای انسان دشوار باشد. | برنامه نویسی سنتی کاملاً به هوش توسعه دهندگان وابسته است. بنابراین، توانایی بسیار محدودی دارد. | گاهی اوقات هوش مصنوعی از ترکیبی از دادهها و قوانین از پیش تعریف شده استفاده میکند که به آن برتری بزرگی در حل کارهای پیچیده با دقت خوب میدهد که برای انسان غیرممکن است. |
| یادگیری ماشینی زیر مجموعه هوش مصنوعی است و اکنون در کارهای مختلف مبتنی بر هوش مصنوعی مانند پاسخگویی به سوالات، ماشینهای خودران و غیره مورد استفاده قرار میگیرد. | برنامه نویسی سنتی اغلب برای ساخت برنامهها و سیستمهای نرم افزاری که دارای عملکرد خاصی هستند استفاده میشود. | هوش مصنوعی یک حوزه گسترده است که شامل کاربردهای بسیاری از جمله پردازش زبان طبیعی، بینایی کامپیوتری و روباتیک است. |
تفاوت بین یادگیری ماشین، برنامه نویسی سنتی و هوش مصنوعی
چرخه حیات یادگیری ماشین
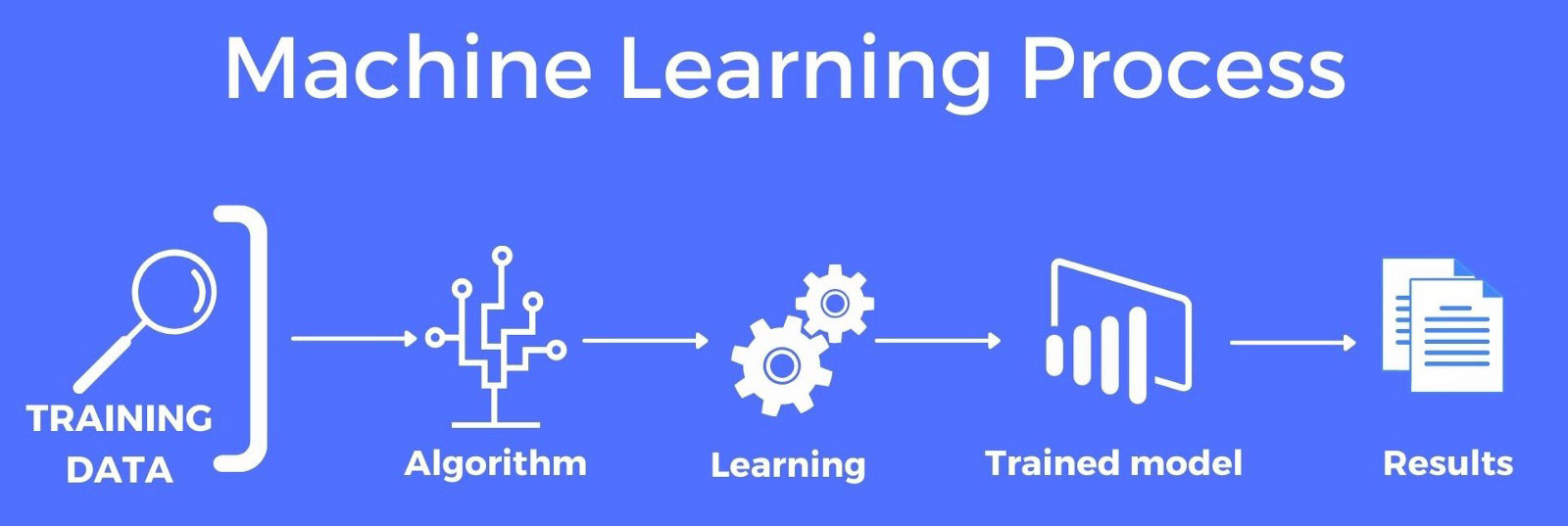
چرخه حیات یک پروژه یادگیری ماشینی شامل یک سری مراحل است که عبارتند از:
۱. مطالعه مشکلات: اولین قدم مطالعه مسئله است. این مرحله شامل درک مشکل کسب و کار و تعریف اهداف مدل است.
۲. جمع آوری دادهها: هنگامی که مشکل به خوبی تعریف شده است، میتوانیم دادههای مربوطه مورد نیاز برای مدل را جمع آوری کنیم. دادهها میتوانند از منابع مختلفی مانند پایگاههای داده یا APIها وب به دست آیند.
۳. آماده سازی دادهها: زمانی که دادههای مربوط به مشکل ما جمع آوری میشود. پس بهتر است دادهها را به درستی بررسی کرده و در قالب دلخواه بسازید تا مدل بتواند الگوهای پنهان را پیدا کند. این کار در مراحل زیر قابل انجام است:
- پاکسازی دادهها
- تبدیل دادهها
- تجزیه و تحلیل دادههای توضیحی و مهندسی ویژگی
- تقسیم مجموعه داده را برای آموزش و تست
بیشتر بخوانید: تجزیه و تحلیل داده چیست؟
۴. انتخاب مدل: مرحله بعدی انتخاب الگوریتم یادگیری ماشین مناسب است که برای مشکل شما مناسب است. این مرحله مستلزم آگاهی از نقاط قوت و ضعف الگوریتمهای مختلف است. گاهی اوقات از چندین مدل استفاده میکنیم و نتایج آنها را با هم مقایسه میکنیم و بهترین مدل را بر اساس نیاز خود انتخاب میکنیم.
۵. مدل سازی و آموزش: پس از انتخاب الگوریتم، باید مدل را بسازید.
- در روش ساخت یادگیری ماشین سنتی فقط چند پارامتر را باید تنظیم کنید
- در روش یادگیری عمیق، باید معماری لایهای را به همراه اندازه ورودی و خروجی، تعداد گرهها در هر لایه و موارد دیگر را تعریف کنید
- پس از آن مدل با استفاده از مجموعه داده از پیش پردازش شده آموزش داده میشود
۶. ارزیابی مدل: هنگامی که مدل آموزش داده شد، میتوان آن را بر روی مجموعه داده تست ارزیابی کرد تا با استفاده از تکنیکهای مختلف مانند گزارش طبقه بندی، دقت، یادآوری، منحنی ROC، خطای میانگین مربع، خطای مطلق و غیره، دقت و عملکرد آن را تعیین کرد.
۷. تنظیم مدل: بر اساس نتایج ارزیابی، ممکن است مدل نیاز به تنظیم یا بهینه سازی برای بهبود عملکرد داشته باشد. این امر شامل بهینه سازی فراپارامترهای مدل است.
۸. استقرار: پس از آموزش و تنظیم مدل، میتوان آن را در یک محیط تولید مستقر کرد تا بر روی دادههای جدید پیش بینی کند. این مرحله مستلزم ادغام مدل در یک سیستم نرم افزاری موجود یا ایجاد یک سیستم جدید برای مدل است.
۹. نظارت و نگهداری: در نهایت، نظارت بر عملکرد مدل در محیط تولید و انجام وظایف تعمیر و نگهداری در صورت نیاز ضروری است. این امر شامل نظارت بر جابجایی دادهها، آموزش مجدد مدل در صورت نیاز و به روز رسانی مدل با در دسترس قرار گرفتن دادههای جدید است.
انواع یادگیری ماشین
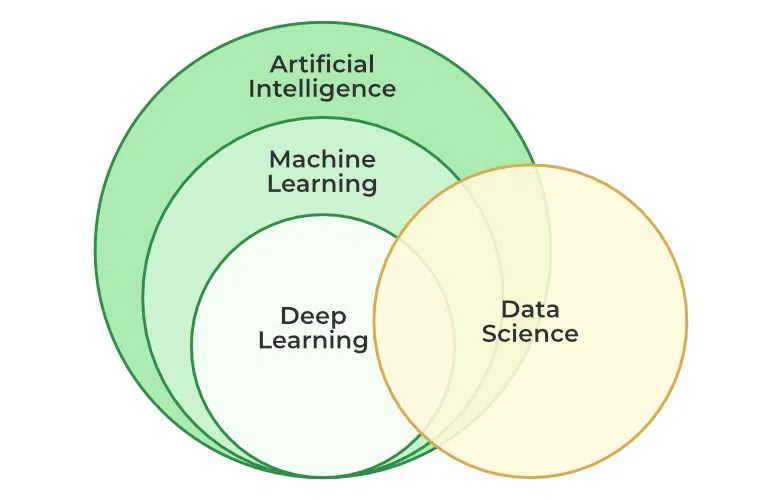
یادگیری ماشین روشهای مختلفی دارد که در ادامه به توضیح هر کدام میپردازیم.
1. یادگیری ماشینی تحت نظارت (Supervised Machine Learning):
یادگیری تحت نظارت نوعی از یادگیری ماشین است که در آن الگوریتم بر روی مجموعه داده برچسبگذاری شده آموزش داده میشود. ماشین میآموزد که ویژگیهای ورودی را بر اساس دادههای آموزشی برچسب گذاری شده به اهداف نگاشت کند. در یادگیری نظارت شده، الگوریتم با ویژگیهای ورودی و برچسبهای خروجی مربوطه ارائه میشود و یاد میگیرد که از این دادهها تعمیم دهد تا روی دادههای جدید و نادیده پیش بینی کند.
دو نوع اصلی یادگیری تحت نظارت وجود دارد:
- رگرسیون: رگرسیون نوعی یادگیری تحت نظارت است که در آن الگوریتم یاد میگیرد که مقادیر پیوسته را بر اساس ویژگیهای ورودی پیش بینی کند. برچسبهای خروجی در رگرسیون مقادیر پیوسته هستند، مانند قیمت سهام و قیمت مسکن. الگوریتم های رگرسیون مختلف در یادگیری ماشین عبارتند از: رگرسیون خطی، رگرسیون چند جملهای، رگرسیون ریج، رگرسیون درخت تصمیم، رگرسیون جنگل تصادفی، رگرسیون بردار پشتیبان و غیره.
- طبقه بندی: طبقه بندی نوعی یادگیری تحت نظارت است که در آن الگوریتم یاد میگیرد که دادههای ورودی را بر اساس ویژگیهای ورودی به یک دسته یا کلاس خاص اختصاص دهد. برچسبهای خروجی در طبقه بندی مقادیر گسسته هستند. الگوریتمهای طبقهبندی مختلف در یادگیری ماشین عبارتند از: رگرسیون لجستیک، درخت تصمیم، ماشین بردار پشتیبان (SVM)، نزدیکترین همسایهها (KNN) و غیره.
2. یادگیری ماشینی بدون نظارت (Unsupervised Machine Learning):
یادگیری بدون نظارت نوعی از یادگیری ماشین است که در آن الگوریتم یاد میگیرد که الگوهای موجود در دادهها را بدون آموزش صریح با استفاده از نمونههای برچسب دار تشخیص دهد. هدف از یادگیری بدون نظارت، کشف ساختار یا توزیع اساسی در دادهها است.
دو نوع اصلی یادگیری بدون نظارت وجود دارد:
- خوشه بندی: الگوریتمهای خوشه بندی نقاط داده مشابه را بر اساس ویژگیهای آنها با هم گروه بندی میکنند. هدف شناسایی گروهها یا خوشههایی از نقاط داده است که مشابه یکدیگر هستند، در حالی که از گروههای دیگر متمایز هستند. برخی از الگوریتم های خوشه بندی محبوب عبارتند از K-means، Hierarchical clustering و DBSCAN.
- کاهش ابعاد: الگوریتمهای کاهش ابعاد، تعداد متغیرهای ورودی در یک مجموعه داده را کاهش میدهند و در عین حال تا حد امکان اطلاعات اصلی را حفظ میکنند. این امر برای کاهش پیچیدگی یک مجموعه داده و آسانتر کردن تصویرسازی و تحلیل آن مفید است. برخی از الگوریتمهای محبوب کاهش ابعاد عبارتند از تجزیه و تحلیل مؤلفه اصلی (PCA)، t-SNE، و رمزگذار خودکار.
کاربردهای مختلف یادگیری ماشین
یادگیری ماشین کاربردهای بسیاری دارد که در ادامه به مهمةرین آنها میپردازیم.
- اتوماسیون: یادگیری ماشین که در هر زمینه ای کاملاً مستقل عمل میکند و نیازی به دخالت انسانی ندارد. به عنوان مثال، رباتها مراحل فرآیند ضروری را در کارخانههای تولیدی انجام میدهند.
- صنعت مالی: یادگیری ماشین در صنعت مالی رو به افزایش است. بانک ها عمدتاً از ML برای یافتن الگوهای درون داده ها و همچنین برای جلوگیری از تقلب استفاده میکنند.
- صنعت بهداشت و درمان: بهداشت و درمان یکی از اولین صنایعی بود که از یادگیری ماشین برای تشخیص تصاویر استفاده کرد.
چالش ها و محدودیت های یادگیری ماشین
- چالش اصلی یادگیری ماشین کمبود داده یا تنوع در مجموعه داده است.
- اگر داده ای در دسترس نباشد، ماشین نمیتواند یاد بگیرد. علاوه بر این، یک مجموعه داده با کمبود تنوع به ماشین کار سختی میدهد.
- یک ماشین برای یادگیری بینش معنادار باید ناهمگونی داشته باشد.
- به ندرت پیش میآید که یک الگوریتم بتواند اطلاعاتی را زمانی که تغییرات وجود ندارد یا تعداد کمی وجود دارد استخراج کند.
پیشنهاد بهفالب : فرایندکاوی چیست؟
جمع بندی
از بهداشت و درمان گرفته تا بخش مالی و حمل و نقل، الگوریتمهای یادگیری ماشین باعث نوآوری و کارایی در بخشهای مختلف میشوند. همانطور که دیدیم، شروع یادگیری ماشین نیازمند پایهای قوی در ریاضیات و برنامه نویسی، درک خوب الگوریتمهای یادگیری ماشین و تجربه عملی کار بر روی پروژهها است.